Concur's Features
Concur supports several features designed to minimize verbal negotiation and make operation simpler for the user.
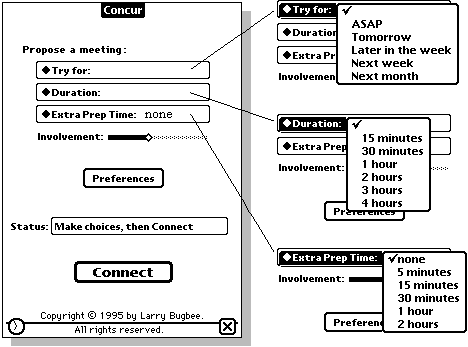
simple meeting specificationThe user is asked to provide a minimum of information to establish a mutually convenient meeting time. Using pull down menus, the user taps their choices for the duration of the meeting and an approximate interval before the meeting is to take place. This is illustrated in Figure 2.
one or both users may propose the meeting
If both users enter the duration and interval, and they disagree, Concur arbitrates this conflict.
single button IR connection
The Apple supplied IR communications modules support asynchronous and bi-directional communications but require programmers or users decide who will use the active mode and who will use the passive mode. This is awkward and defeats the goal of voiceless communications. Concur incorporates a single activation button, "Connect," and arbitrates the use of the active and passive modes to simplify operations. See Figure 2.
simple user acceptance/rejection actions
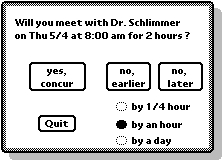
Proposed meeting times are accompanied with several buttons for the user to express the desired action. One button, titled "Concur," constitutes acceptance of the proposed time and if both users concur, the meeting will be scheduled. Two other buttons are labeled "Earlier" and "Later" to causing the program to move forward or backward in time when looking for another time to propose. A fourth button, captioned "Quit," allows the user to abort the proceedings. See Figure 3.
case-based machine learning model
Concur learns the user's preferences and as the confidence level increases, meetings are automatically proposed away from undesired times using a case-based reasoner. The case frame includes such attributes as the hour of the day, the day of the week, the duration of the meeting, the person meeting with and whether the meeting is immediately behind or ahead of another. Provision will be made for the total number of meeting hours already scheduled that day and the next and previous days. The user may control the weighting of the various attributes nearest neighbor calculation weights.
real-time operationConcur is designed to be efficient and operate in real-time.
algorithms valid for more than two machines
While the IR communications are limited to two Newtons, the internal algorithms are designed to work for N machines.
IR Connection Mode Arbitration
A primary goal of Concur is to minimize the amount of verbal negotiation required between the parties suggesting the design of a single button connection module. IR communications support provided by Apple is mode sensitive. That is, while attempting an IR connection, the Newton OS requires that one Newton be in connect or active mode and the other in listen or passive mode. Once a connection is effected, the protocol becomes true peer-to-peer. If a naive design were implemented, this would require Concur users to decide who will press the connect button and who will press the listen button.
Concur's IR class has a single connection method that alternates between the connect mode and the listen mode to effect the connection. These modes are chosen at random and are held for random periods of time between 2 and 4 seconds. Typically, connections are achieved within a few seconds but if no connection is achieved within 15 seconds, the users are so advised and asked if they want to try again.
Transmitted messages are simply Newton OS frames. They may, therefore, contain any of the data types native to Newton including other frames and arrays. All of the data is "flattened" for transmission and reconstructed upon receipt. This approach is quite simple and flexible making reuse of this class definition attractive.
As soon as a connection is effected, version number strings are exchanged to ensure compatible versions are talking with each other. The connect method is passed the address of a routine to call when there is a connection and an internally generated frame is passed containing a slot titled "connected." This same routine is called when an incoming message is received and the frame of the incoming transmission is passed. This allows the application designer the ability to provide one common message handler for all of the communications including the original connection.
One heuristic is applied with the goal of speeding the connection process. If a user selected a meeting "try for" or a duration, then that user is started in the "connect" mode. This is communicated to the method by a simple boolean flag allowing other, or no, criteria to be applied should this class definition be reused in other applications.
The transmission has increased reliability to intermittent
connections because of an acknowledgment and retry scheme. Each
transmission includes a serial number that if not acknowledged
within 1 second, the packet is retransmitted. If, after 10 retries,
the packet is still not acknowledged, a broken connection message
is presented to the user via one of the call back addresses.
Calculation of Mutually Agreeable Meeting Times
Arriving at mutually agreeable meeting times computationally is easier if the process is divided into several smaller steps. Concur breaks this process down by first building an array of time intervals that one cannot meet, hence its name, the Cannot array. This array is simply a collection of time intervals that are not available for meetings and may overlap. Scheduled activities in the CalendarSoup and possible repeating activities in the RepeatingMeetings Soup are extracted using the built-in global function GetAllMeetings(). It returns an array of frames from which Concur extracts the meeting start time and duration for addition to the Cannot array.
The Cannot array is sorted to simplify the construction of the Avail array which is an array of non-overlapping time intervals that are available and sufficiently long for the meeting and any requested preparation (or travel) time. When two or more Avail arrays are assembled for the purpose of finding a mutually agreeable time, they are organized in an AA array to present all of these times in a uniform manner to other calculation routines. The AA array, then, is simply an array of Avail arrays where the zeroth element is the local Avail array.
The process begins with one user, or both, selecting a "nominal interval" of time to elapse before the meeting. This is the "try for" interval and a pick list on Concur's main view is used to input its value. This is the time interval between now (when Concur is running) and an approximate time of when the meeting is to occur. For example, if the user selects "later in the week," this means that Concur is to try to find a meeting time sometime after the day after tomorrow (nominally 2 days hence). One or both users must also select a proposed meeting duration.
This information is exchanged between the Newtons. If both happen to select a "try for" time, the later one is used. If both select a meeting duration, the longer one is used. Both Newtons calculate their Cannot and Avail arrays and exchange their Avail arrays periodically during the process. Finally, two or more Avail arrays are combined to form an AA array which is examined to find a mutually agreeable meeting time.
Later, when the user rejects presented times, Concur adds a new interval to the Cannot array so the rejected time will be ignored in future calculations. A new Avail array is constructed if 1) the direction of search changes and 2) the Cannot array has changed since the previous Avail array was constructed.
The time and duration to be added to the Cannot array is dependent on the direction of search and the amount of time the user asked be skipped (15 min, 1 hr or 1 day). If the direction is forward, the time and skip interval are added. If the direction is back in time, the time is the end of the meeting minus the skip interval and the duration is the skip interval. This is the proper calculation to not again propose the same time but still allow other meetings to be scheduled that might overlap. For example, a 2 hour meeting at 9am might be rejected but a 9:15 might be acceptable. Likewise, a 2 hour meeting at 2pm might be rejected but the same meeting at 1:30pm might be acceptable.
The algorithms use a not-before-time or nbt
and not-after-time or nat to bracket the search. These
values are determined by the nominal interval and a date
30 days hence. In actuality, the time calculations support an
interval between "now" and 30 days after the nominal
interval and are stored as g.NBT
and g.NAT
in the global data. This is to support the user being able to
specify an earlier or a later time.
The Case-based Reasoner and Choice of Indices
Through the process of accepting and rejecting proposed times, Concur learns the preferences of its user by watching the user's actions and adding observations to a case base. Eventually, the quality of and the confidence in Concur's recommendations improves and, perhaps, the user will grant Concur authority to operate autonomously instead of making recommendations and asking for the user's decision.
Concur uses a weighted nearest neighbor algorithm to choose its exemplar. Each attribute's distance, or degree of mismatch between the probe's attribute value and the case's attribute value, is calculated and the more important attributes are given higher weights. These weighted distances are summed to provide a total distance for each case and the case with the lowest distance is selected as the exemplar.
The actual weighting factors are a combination of a normalization factor and a importance factor. Multiplying the difference by these factors provides that attribute's contribution to the distance. Once the attribute's contribution to the total distance is determined, we provide the user with a slider, or control, to bias the attributes over a range of 0 to 10. This gives the user a high degree of control over how the case base can be applied to future meeting negotiation situations. This approach, unfortunately, does not affect the choice of indices and poor candidate cases could result.
Initially there will be no entries in Concur's case base but after repeated use, it will grow in size and quality. While the case base is small, the time to evaluate all cases to find the nearest neighbor is also small and probably doesn't justify the cost of an indexing scheme. This situation changes as the case base grows. An artificial subdivision of the database is needed to keep search times reasonable but the challenge is to subdivide that database in such a way that good cases will not be missed. The earlier discussion of index attributes guided this definition of Concur's indexes.
Step 1 - Choose a Vocabulary
The first step is to choose data elements that describe the situation. They should be readily accessible, concrete and when taken together, adequate. If there are structural features that need description, attributes should be defined. If abstraction is needed, consider creating new attributes if the original data is also needed.
Considering the problem, the following data elements
were initially identified as available for each case in Concur's
case base.
- meeting start time
- day of week
- meeting duration
- person/group meet with
- date and time dictated by others
- time interval after previous meeting
- time interval before next meeting
- number of meeting hours that same day
- last minute preparation (little = 0, lot = 5)
- deadline for meeting
- measure of involvement (presiding = 5, simply attending = 0)
- number of meeting hours in previous day
- number of meeting hours in following day
- action: accepted or direction and distance
The date, time and day-of-week data elements should be sufficiently concrete. "involvement " is subjective and should work. As for structural features, this is a simple problem and structural features are not relevant.
"preparation" appears to be more a constraint in scheduling than an item affecting user preferences. The user should indicate the amount of time required and that should be honored in preparing a schedule. We will remove it from the list.
For many people, "meeting start time" and "meeting duration" measured to the nearest minute would be too specific. For example, any meeting that were to begin between 9:30 and 10:30 AM would be considered a "mid-morning" meeting and would be sufficient to understand the user's meeting preferences. Until we conduct a correlation analysis to determine the true contribution of each of these attributes to the solution, we ought to establish two additional data elements titled "general meeting start time" and "general meeting duration". (See the revised list of data elements below. The classifications are arbitrary and their actual boundary values will be chosen later.)
"time interval after previous meeting" and "time interval before next meeting" are intended to identify the availability of time for last minute preparation. Some abstraction seems appropriate with little need to retain the actual number of minutes. Also, the use of these categories solves another problem, namely, are the hours before a Monday morning meeting in the same class as the number of hours before a Tuesday morning meeting or another later in the day? Simply calculating the difference would be misleading.
"deadline for meeting" was conceived to be simply true or false to the question, "Is there a deadline associated with this meeting?" When this is true, one could argue that the action associated with this case is not "reliable" because that action may not be in keeping with the user's preferences.
"date and time dictated by others" might be a piece of data available to us but it is not a discretionary preference item. It might, however, affect other preference weights in the same way "deadline for meeting" can affect the reliability of the recommendation. Both of these data elements will be combined into a single "major scheduling constraint" with a true/false data value. A user might want to weigh this item heavily.
"person/group meet with" is intended to be a free-form character string and will not normally be useful in nearest neighbor calculations. Because Concur will be getting the name field automatically from the user's personal preferences, it should be identical for the same user over time and compare well. Only an equal or not equal test would be meaningful.
The revised list of data elements became as follows.
- meeting start time
- general meeting start time (
very early morning = before 7:30,
early morning = 7:45-8:45,
mid-morning 9:00-10:30,
late morning = 10:45-11:30,
noon = 11:45-12:30,
early afternoon = 12:45-1:45,
afternoon = 2:00-3:15,
late afternoon = 3:30-4:45,
early evening = 5-6:45,
evening = 7:00-9:00,
late evening = 9:00-10:00,
late night = after 10 PM)
- day of week (0 = Sun, 1 = Mon … 6 = Sat)
- meeting duration
- general meeting duration (
short = 0-30 minutes,
medium = over 30 minutes to 3 hours,
long = 3-5 hours,
all day = over 5 hours)
- person/group meet with
- major scheduling constraint (true/false)
- involvement (simply attending = 0,
presiding = 5)
- time interval after previous meeting (
0 to 5 minutes, 6 to 20 minutes, over 20 minutes to 1 hour, 1 to 2 hours, 2 to 4 hours, over 4 hours) - time interval before next meeting (same as #9 above)
- number of meeting hours that same day
- number of meeting hours in previous day
- number of meeting hours in following day
- action: accepted or direction and distance
15. time last an exemplar: time this case was last used as an exemplar, zero if never.
Probe cases are prepared without values for attributes #14 and #15.
Step 2 - Define the Matching Algorithm
The second step is to define an equation that will calculate the combined differences between a case in the case base and the actual observation or probe. The expression for arithmetic attributes is often the difference in the values. Other attributes may be too difficult to compare other than by simply saying they are equal or not. All of these expressions will need to be summed to give the total distance between the probe and the case in the case base.
Unfortunately, not all attributes should have equal weight. Here the designer needs to examine a number of situations and weigh them so that if all but two items match, each has an "equal effect" on the distance function. Admittedly this a subjective measure on the part of the designer, but it is all that is available. If the weighting factor were to be split into a normalization factor and an importance factor, designer biases can be mitigated by the user.
Concur's weighting factors were each divided into the two factors. The default importance factor was assumed to be 5 and the normalization factor was calculated so that, from the designer's perspective, differences in each attribute would have about the same effect on the distance computation. The user is then allowed to set each attribute's importance factor to a value between 0 and 10 and by so doing, capture notions of importance. This allows the biases of the designer to be overcome to some degree.
Figure 4 is Concur's distance function. All times
are measured in minutes and the equality tests return 1 or 0 for
true or false.

"time interval after previous meeting" and "last minute preparation desired" are two attributes that should be taken together. If we need a lot of time and there is a lot of time, there is no problem and likewise, if we don't need any time, it doesn't matter how much time is available. On the other hand, if we need time and there is none we have a complication. Concur uses a compound factor for these two attributes.
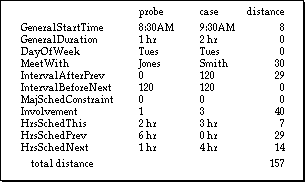
For example, the distance for a probe and a case
with the certain attribute values might be calculated as shown
in Figure 6. Studying the results, one might conclude too much
weight is being given to the person meeting with but with a slider,
the user can make adjustments. Unfortunately, the user is probably
not sufficiently informed to make good choices.
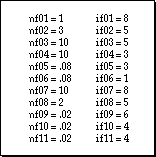
Step 3 - Rank Predictive Features
The third step is to identify and rank those attributes that are likely to be predictive. One way is to look at the user's importance factors and choose the top ones. If that is not practical, the designer can make arbitrary choices. A technique to mitigate biases introduced at this stage will be discussed later.
Without the benefit of a set of real-world weights,
choose those attributes that seem to be the most important as
candidate indices. The major ones selected for Concur are as
follows.
- general start time
- major scheduling constraint
- number of meeting hours same day
- general duration
- day of week
- degree of involvement
Step 4 - Prune the List
The purpose of an index is to subdivide a database for quick access to records of interest. In step 4, this list should be pruned by removing those attributes that might not make good indices. A good candidate would divide the data base into sufficiently small groups where examining each member of the group is acceptable and there would be sufficient members in the group so as to be interesting. For example, a boolean attribute is not likely a good candidate because it divides the data base into only two parts.
Concur uses "general start time," "number of meeting hours same day" and "general duration" as its indices. "major scheduling constraint" was dropped because it is a binary attribute and would serve only to divide the case base into two, and probably unequal, parts. Further, it seems more like a predictor of cases that should be excluded. [See Kol88, p358] Rather than exclude such cases, we will simply give this attribute a high weight.
It searches on each index and merges the selections into a common set of cases for a nearest neighbor calculation. If a good case just misses being selected by one index, it may be strong enough to match the criteria of another index and be selected.
A fourth index, "time last an exemplar", was created should the user choose to reduce the size of the case base.
Step 5- Define the Indexing Data Structure
In CBR we do not want to miss evaluating cases simply because an index directed us away from a truly relevant case. There are several ways to address this problem and one is to expand the search down both branches of a tree when boundary conditions are detected. [Ull88] Another solution is to search several indices, and merge the found cases into one common list of relevant cases. Use of this technique mitigates, but does not remove, the designer's bias introduced in step 3 above.
The Newton OS has a built-in indexing facility and
because the Newton stores all of its data in memory (there being
no secondary store), searches are relatively quick. Multiple
equal keys are supported and there are built-in routines to retrieve
the cases in order, if desired. Concur takes advantage of this
facility.
Original paper: Copyright © 1995 by Larry Bugbee
This HTML rendering: Copyright © 1997 by Larry Bugbee
All rights reserved.